Pratik Thanki

Grafana Cloud
1 February 2021Monitoring applications with Grafana
On the back of the Grafana announcement earlier this year I was excited to use the new free Grafana Cloud to monitor my NFL play-by-play API - FourthDown. In this post I’ll cover how I use Grafana Cloud to proactively monitor performance, the powerful capabilities of Prometheus and Jaeger in my observability stack.
Background
Application observability is built on three key components:
-
Logging: information about events happening in the system, this can vary from instances of throwing out of memory exceptions and app configuration on startup not reflecting expected values. Useful for getting a complete understanding of what has occurred in the system.
-
Tracing: information about end-to-end requests received by the system. A trace is similar to a stack trace spanning multiple applications. Traces are a good starting point in identifying potential bottlenecks in application performance. Like asynchronous web requests, serialization or data processing.
-
Metrics: real-time information of how the system is performing. KPIs can be defined to build alerts, allowing for proactive steps when performance degrades. Compared to logs and traces, the amount of data collected using metrics remains constant as the system load increases. Application problems are realized through alerting when metrics exceed some threshold. For example, CPU usage being higher than before, increase in 5xx requests or average response times.
You can read more about Grafana Clound integrations in this blog post.
Best Practices
It can be daunting to find and define application metrics, two well-known methods for what metrics to add to a given system are defined below.
The USE method for resources - channels, queues, CPUs, memory, disks, etc.
- Utilization: some time aggregation (median, average, percetile) that the resource was busy (e.g., disk at 90% I/O utilization)
- Saturation: the extent to which work/tasks are queued (or denied) that can’t be serviced (e.g. queue length for incoming messages)
- Errors: count of errors and by type (4xx, 5xx, etc.)
The RED method for request-handling services:
- Rate
- Error Rate
- Durations (or distribution)
You can read more about each here, there are a number of Prometheus-specific instrumentation best practices.
Another popular method defined by Google’s Site Reliability Engineering book is the The Four Golden Signals
The books mentions,“If you can only measure four metrics of your user-facing system, focus on these four.”:
- Latency: the time it takes to serve requests
- Traffic: measure of demand placed on the application or service
- Errors: the rate of requests that fail
- Saturation: how “full” your service is
“If you measure all four golden signals and page a human when one signal is problematic (or, in the case of saturation, nearly problematic), your service will be at least decently covered by monitoring.”
Tracing
Leveraging tracing allowed me to find and remove bottlenecks that impacted end-user performance. In this example,
multiple HTTP web requests can be performed asynchronously through System.Threading.Tasks:
Request performance was not at the level I was aiming for. Upon examining request traces I realized the synchronous manner of web requests:
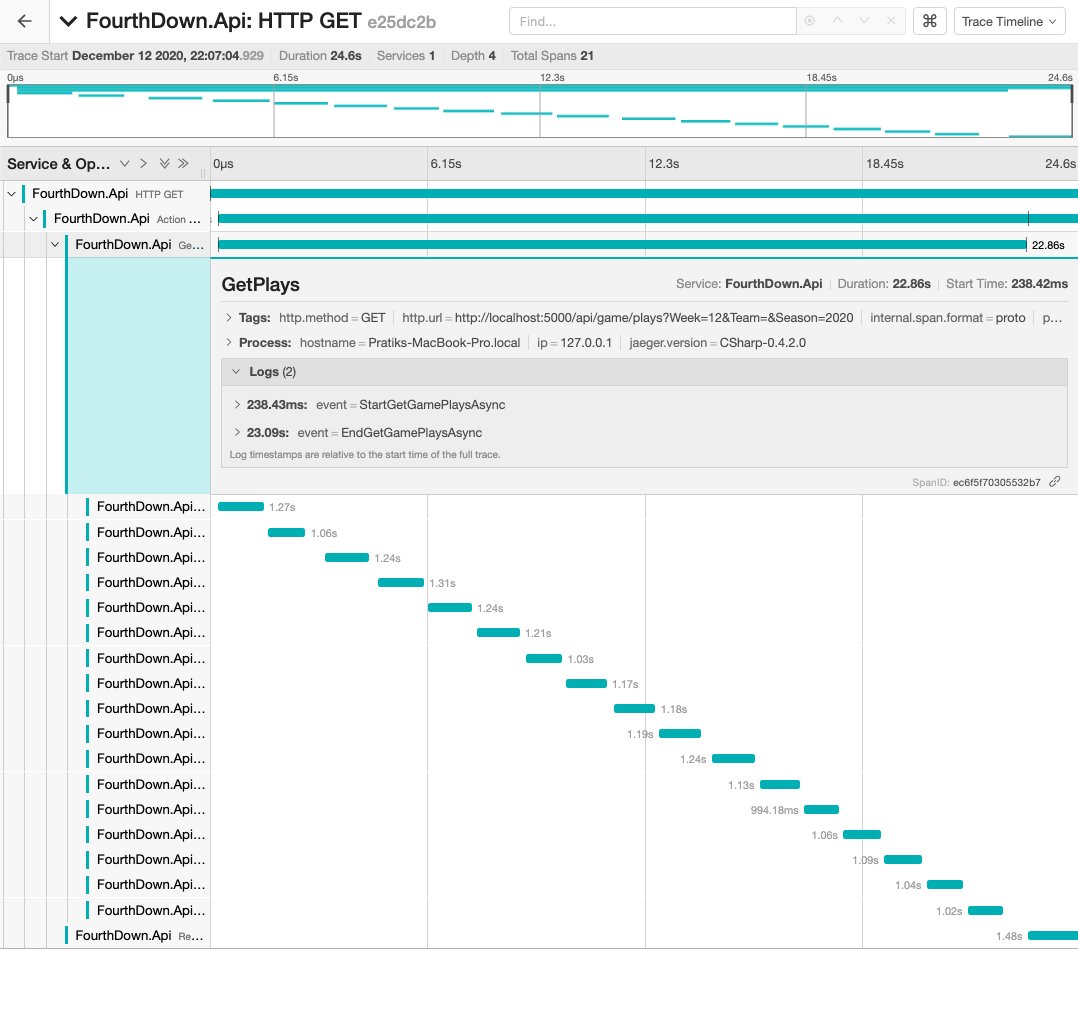
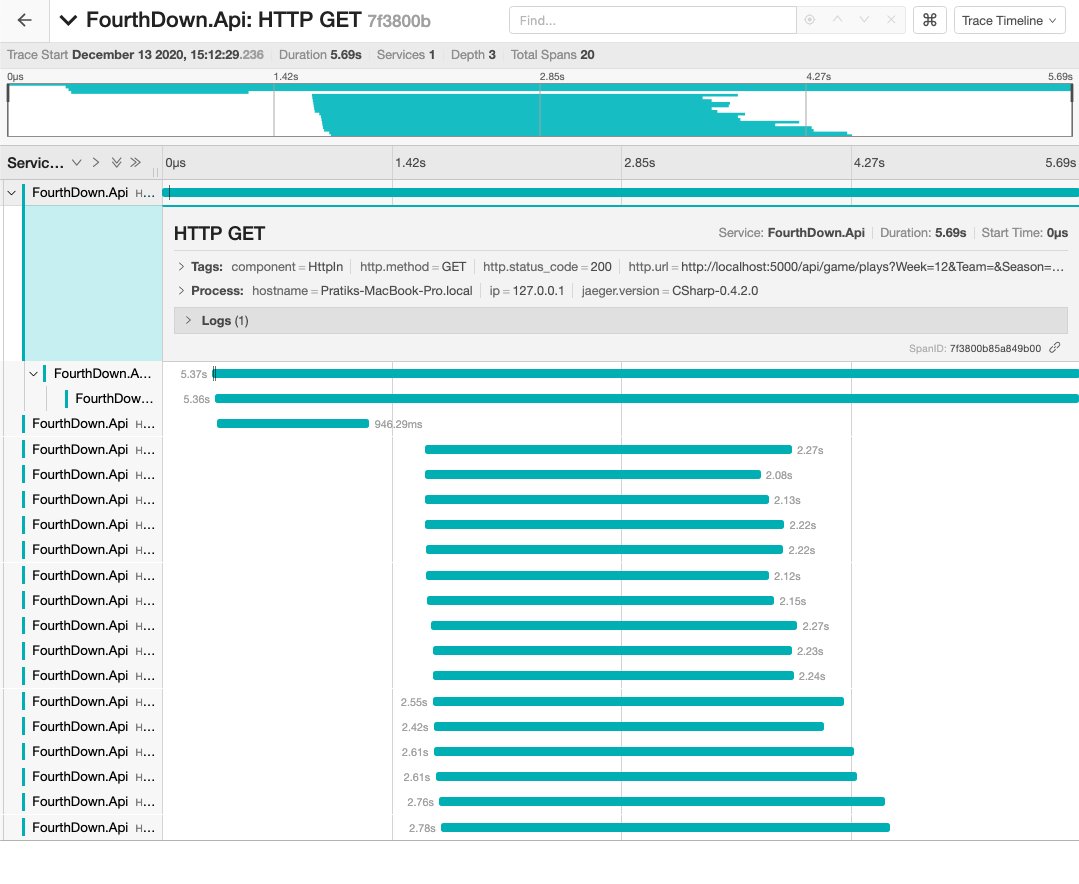
Executing requests through Task.WhenAll will complete when all of the supplied tasks have completed. This significantly
improved response times and resulted in the following trace:
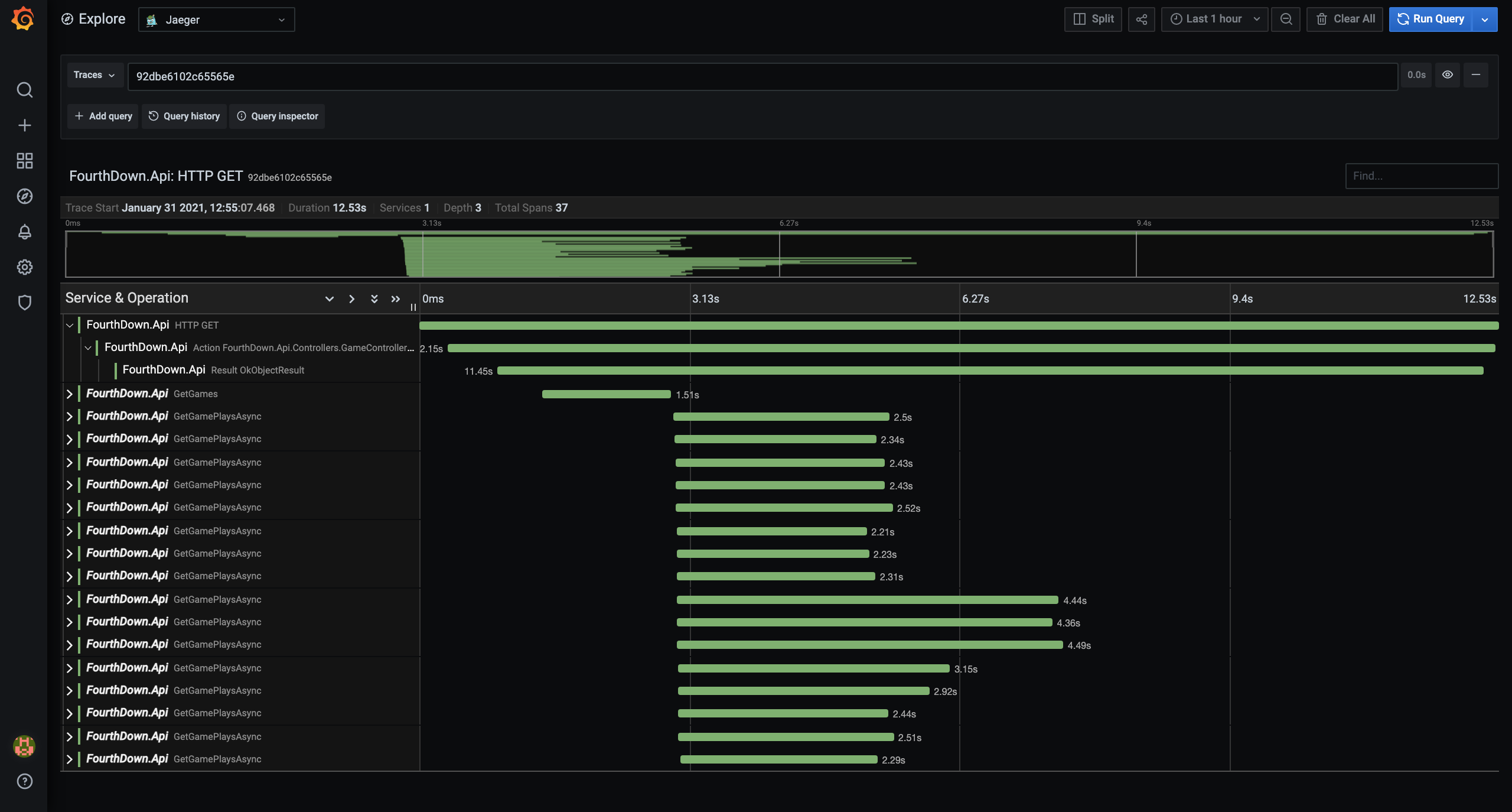
The Grafana-Jaeger integration view:
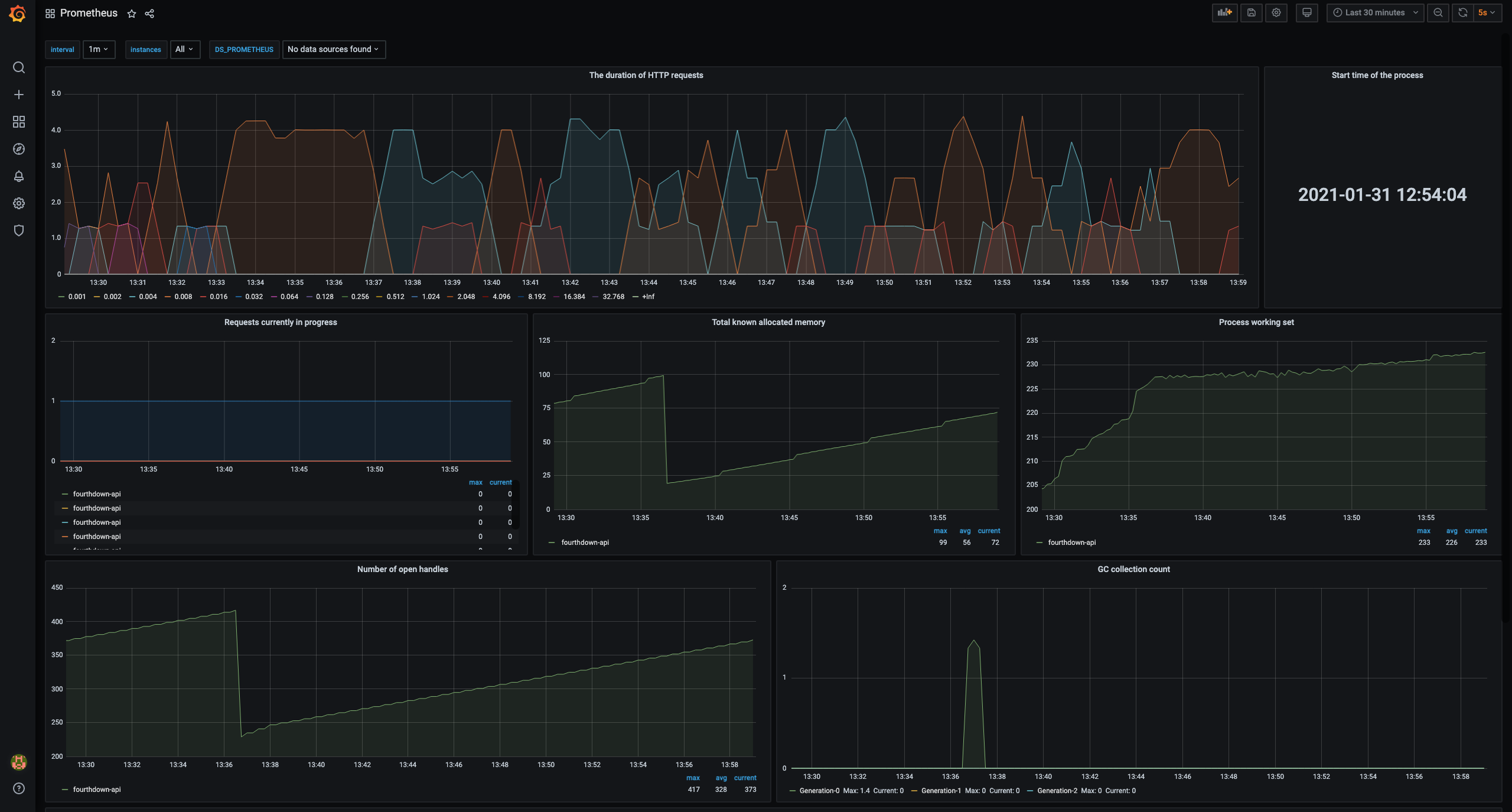
Monitoring
Combining the methods described above and the capabilities of libraries available for ASP.NET Core allowed me to create optimal dashboards.
Takeaways
Getting started with Grafana Cloud intrigued me to look further into further aspects of monitoring and appreciate the open-source observability eco-system; from Prometheus, Jaeger and Grafana. Not to mention other frameworks and libraries I didn’t use for this project. You can read more here on observability in ASP.NET Core.
Getting started with the API in any language is super simple, you can read this post with code snippet - FourthDown API Samples.
Thanks for reading!